【导读】无需人工标示,吞下17亿张图片,Meta用自监督学习炼出「视觉全能王」!NASA已将它送上火星,医疗、卫星、自动驾驶范畴集体欢腾。
17亿张图片,Meta训出70亿参数「视觉巨兽」DINOv3,彻底开源了!
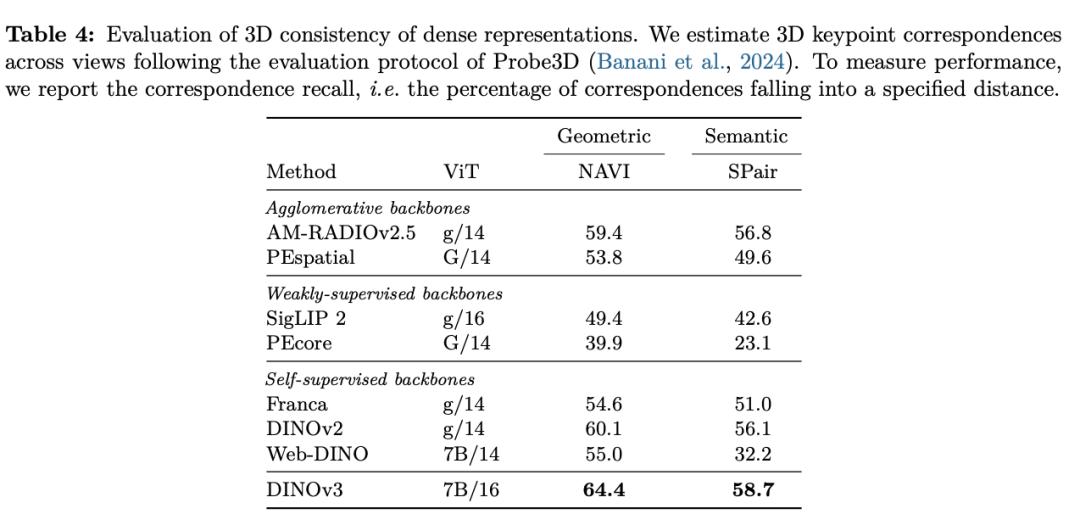
经过自监督学习(SSL)练习,DINOv3可生成强壮且高分辨率的图画特征。
在多个密布猜测使命中,这是单一固定的视觉主干网络第一次逾越专用解决方案。
DINOv3从头界说核算机视觉功能天花板,在多个基准测验中改写或迫临最佳作用!
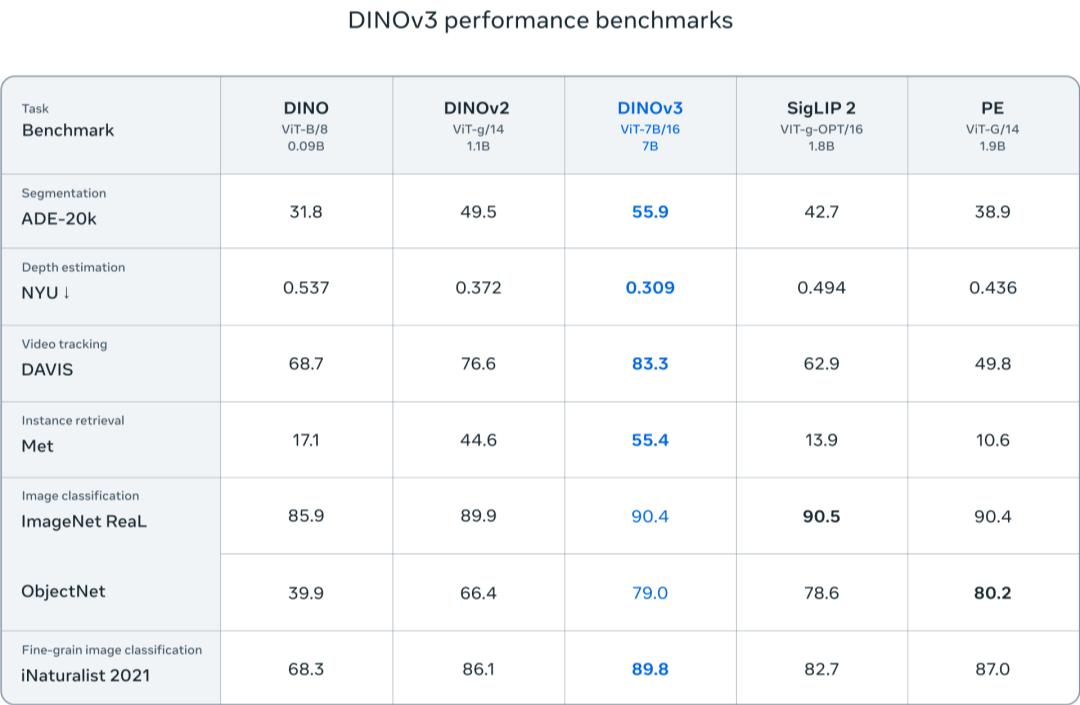
美国的NASA乃至已在火星探究上用上了DINOv3。这是真上天了!
就在我们认为Meta在AI比赛上被筛选之时,Meta这次总算意气昂扬。

并且,这次Meta是真开源:DINOv3不只可商用,还开源了完好的预练习主干网络、适配器、练习与评价代码等「全流程」。

项目地址:https://github.com/facebookresearch/dinov3
悉数checkpoint:https://huggingface.co/collections/facebook/dinov3-68924841bd6b561778e31009
DINOv3亮点如下:
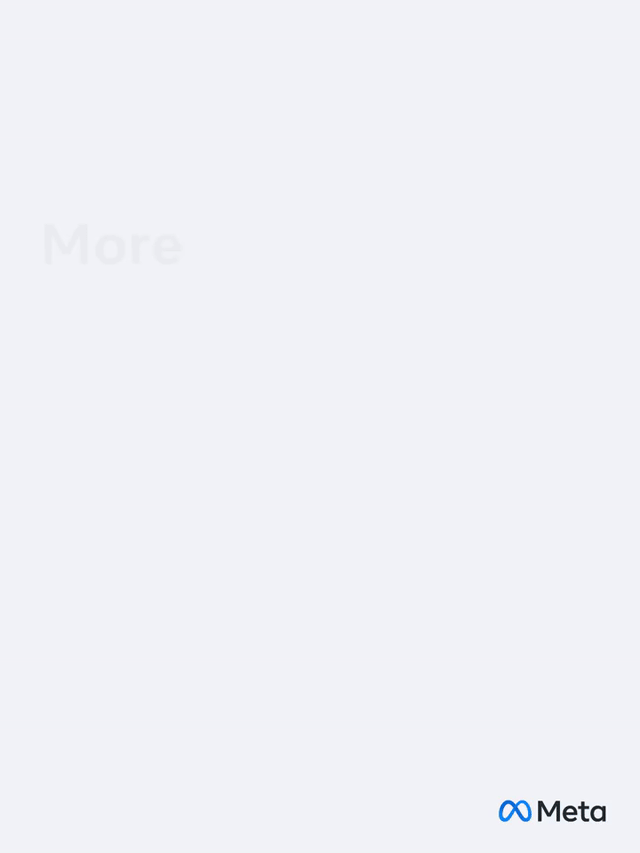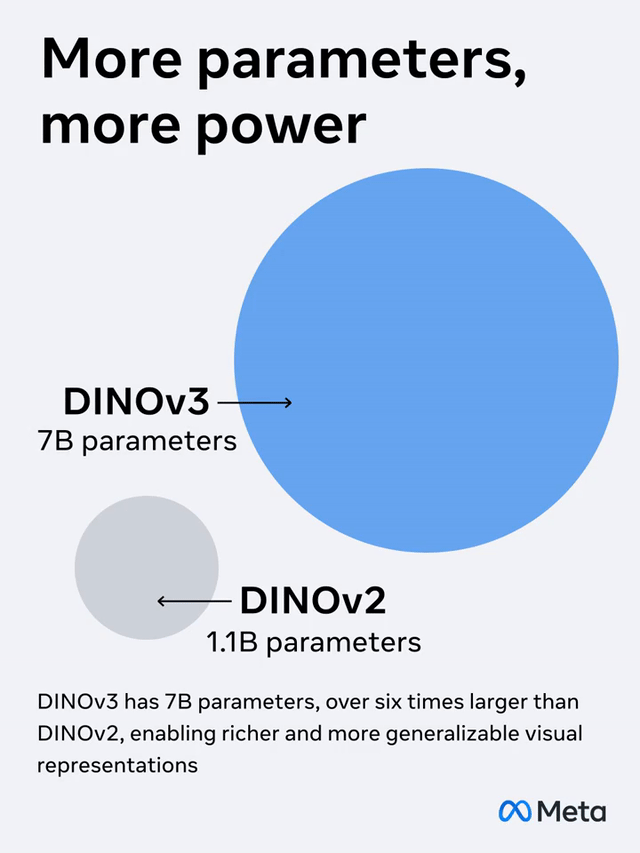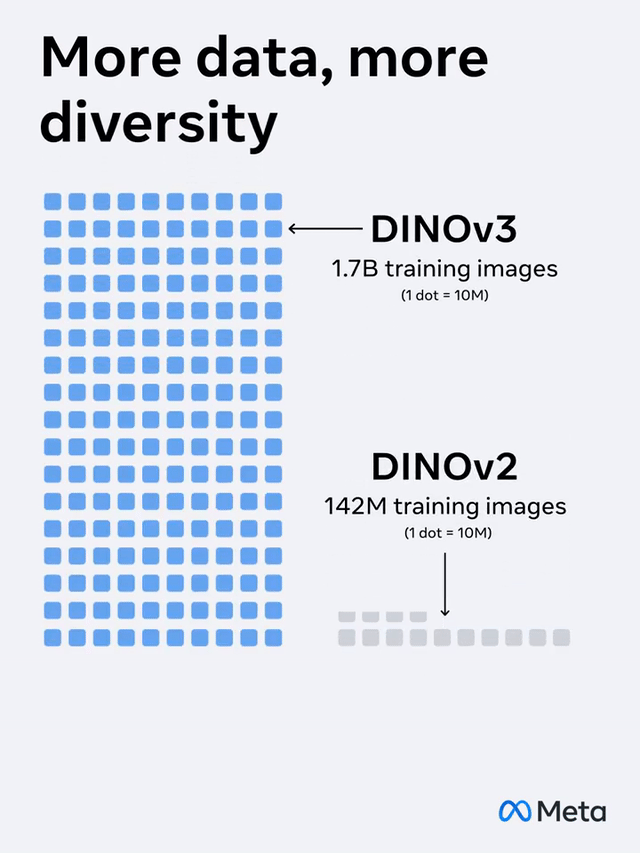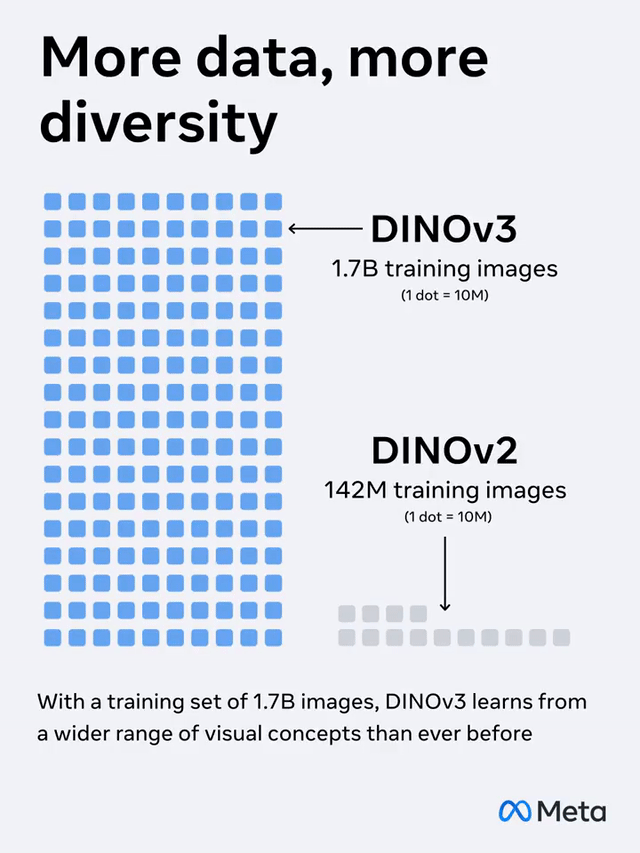
SSL支撑在无需标签的情况下对含17亿张图画、70亿参数的模型进行练习,适用于标示资源稀缺的场景,包括卫星图画。
生成超卓的高分辨率特征,并在密布猜测使命上完结最先进的功能。
多样化的视觉使命和范畴运用,悉数选用冻住主干(无需微调)。
包括蒸馏后更小的模型(ViT-B、ViT-L和ConvNeXt 变体,以完结灵敏布置。
自监督学习的新胜利
自监督学习无需人工标示数据即可独立学习,已成为现代机器学习范畴的主导范式。
大言语模型兴起全在于此:经过在海量文本语料库上进行预练习来获取通用表征。但是,核算机视觉范畴的开展却相对滞后,因为现在最强壮的图画编码模型在练习时仍严峻依靠人工生成的元数据,例如网络图片标题。
DINOv3改变了这一切:
DINOv3提出了新的无监督学习技能,极大地减少了练习所需的时刻和资源。
这种免标示的办法特别适用于标示稀缺、本钱昂扬或底子无法获取标示的场景。例如,运用卫星印象预练习的 DINOv3主干网络,在树冠高度估量等下流使命中体现杰出。
不只能加快现有运用的开展,DINOv买宠物网站推&#韩国一天交换无删减33616;无删减版3还有或许解锁全新的运用场景,终将成为你9无删减迅雷推动医疗保健、环境监测、自动驾驶、零售、制作等职业的前进,完结更精准、高效的大规划视觉了解。
前所未有:自监督学习逾越弱监督
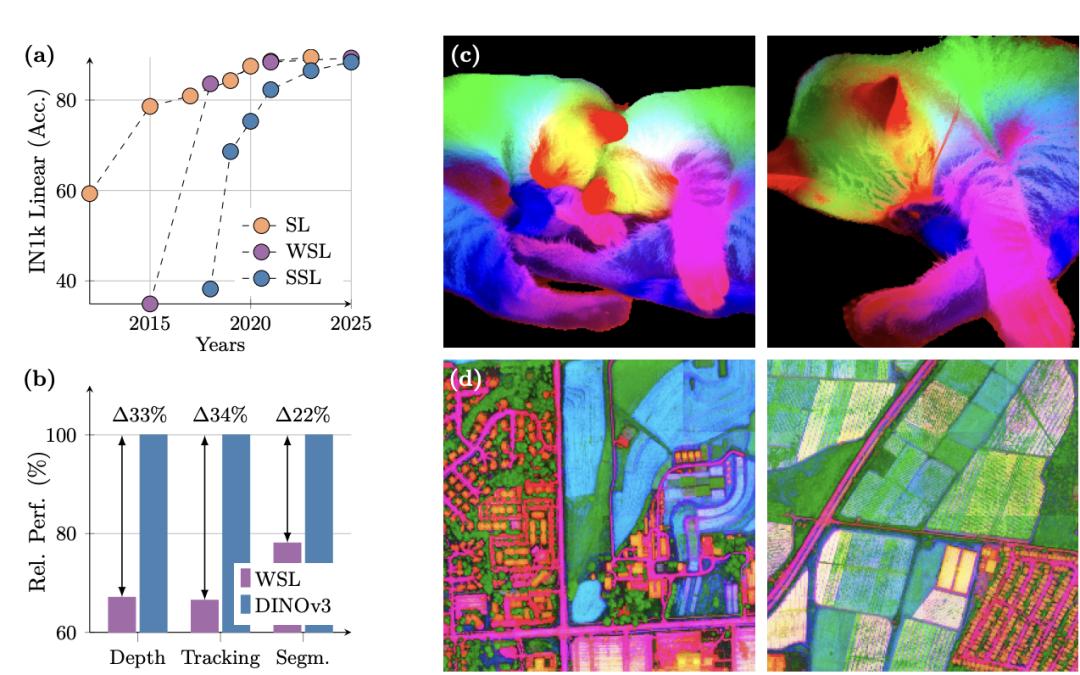
DINOv3再次改写了里程碑——初次证明自监督学习(SSL)模型能够在广泛使命中逾越弱监督模型的体现。
DINOv3连续了DINO算法,不需求任何元数据输入,但这次所需练习算力仅为以往办法的一小部分,却仍然能产出极端强壮的视觉根底模型。

凭仗这些全新改善,在竞赛剧烈的下流使命(如在冻住权重条件下的方针检测)中,DINOv3也能取得当时最优体现。
这意味着研讨者和开发者无需为特定使命进行微调,即可将其直接运用于更广泛、更高效的场景。
此外,DINO办法并未针对特定图画模态进行优化,它不只适用于网络图画,还能推行到那些标示极端困难或本钱昂扬的范畴。
DINOv2现已运用海量无标示数据,支撑了安排病理学、内窥镜及医学印象等方向的确诊与科研工作。而在卫星与航空印象范畴,数据量巨大且杂乱,使人工标示简直不可行。
DINOv3能够将这些丰厚的数据集用于练习一个通用主干网络(single backbone),并跨不同类型的卫星图画,完结环境监测、城市规划、灾祸应对等多种运用。
DINOv3已在实践国际产生了影响。
国际资源研讨所(WRI) 正在运用新模型监测森林采伐并支撑生态修正,协助当地集体维护软弱的生态系统。依托DINOv3,WRI剖析卫星印象,检测受影响生态区域的树木损失和土地运用改变。
DINOv3带来的精度提高,使其能够自动化气候金融拨款流程,经过验证修正作用来下降交易本钱,加快资金流向本地小型安排。
例如,与DINOv2比较,在对肯尼亚某区域的树冠高度进行丈量时,运用卫星与航空印象练习的DINOv3将平均误差从4.1 米降至1.2 米。
无需微调也能完结高效Scaling
相较前一代DINOv2,DINOv3在规划上有了大幅提高:
模型参数扩展了7倍,练习数据量也提高了12倍。
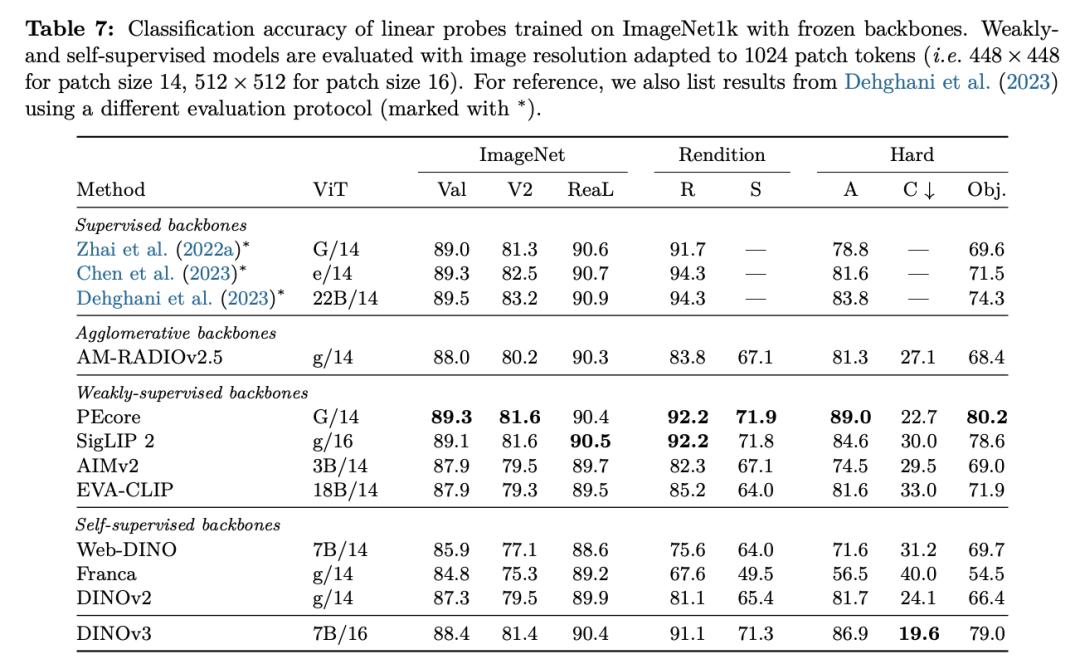
终将成为你9无删减迅雷rong>韩国一天交换无删减>为了验证它的多样性,买宠物网站推荐无删减版在15项不同的视觉使命和逾越60个基准测验上,Meta团队全面评价了DINOv3。
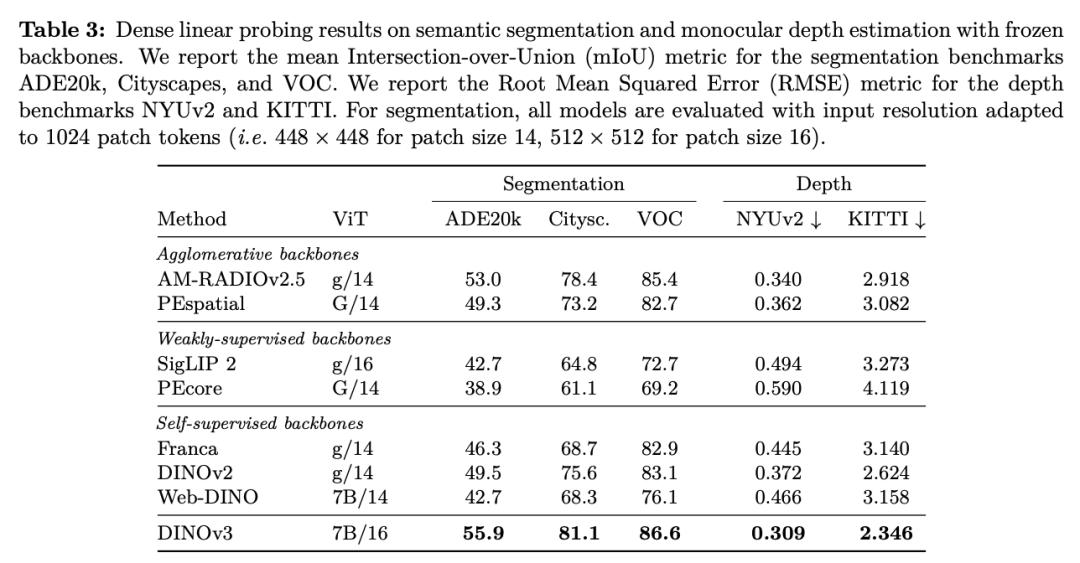
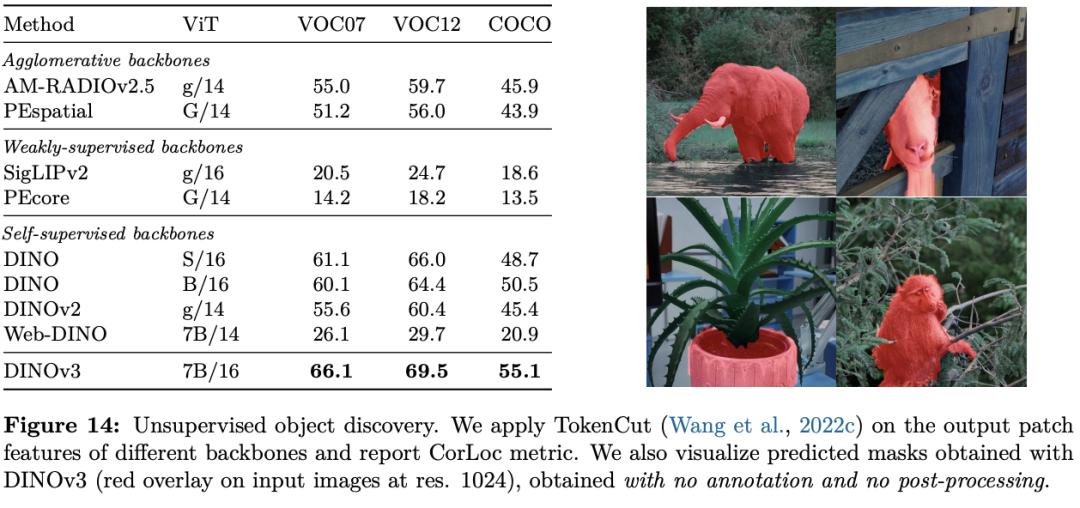
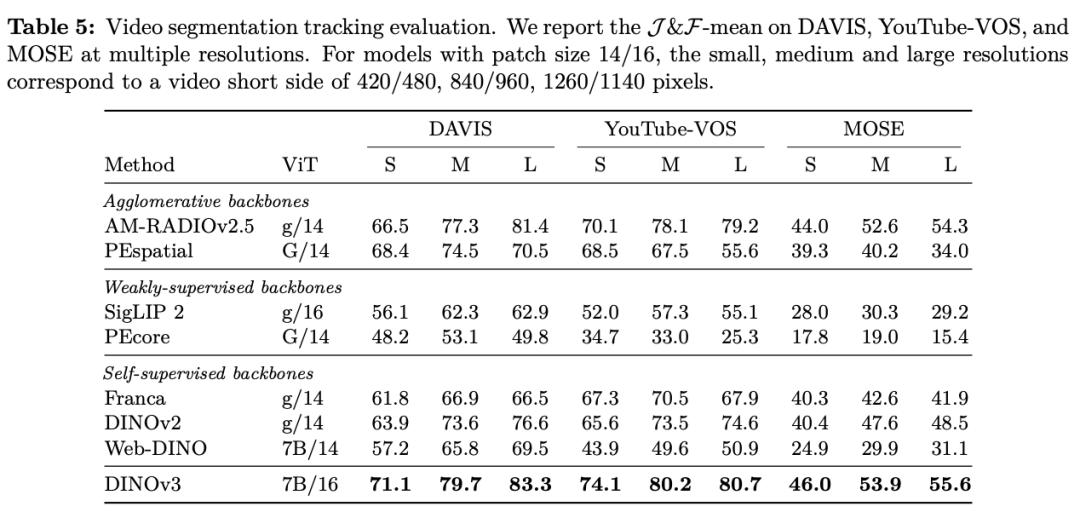
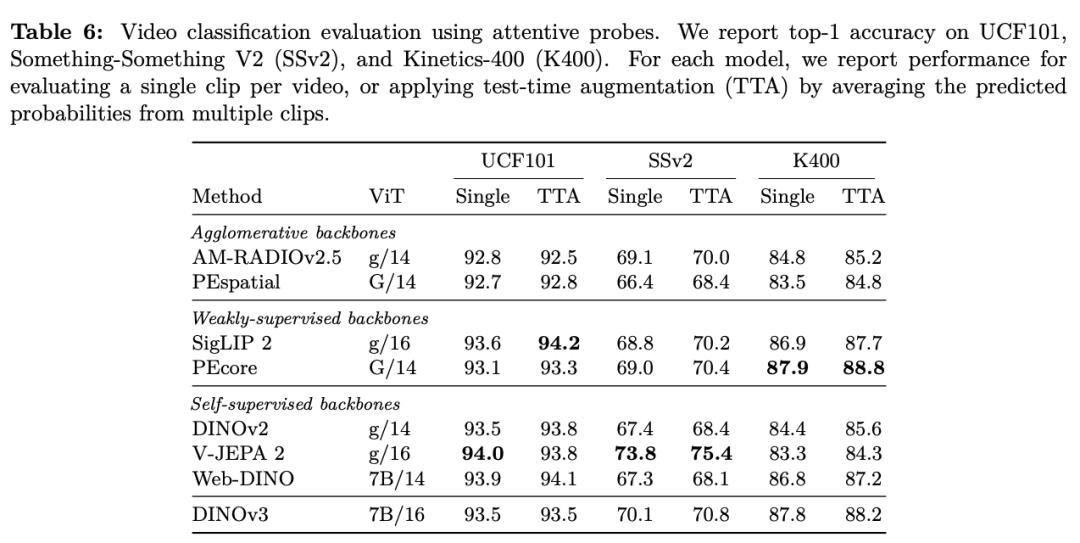
在各种密布猜测(dense prediction)使命中,DINOv3的主干网络体现超卓,展现出对场景结构和物理特点的深刻了解。
DINOv3 能提取出丰厚的密布特征(dense features),为图画中每个像素生成包括可丈量特点的浮点向量。这些特征不只能协助辨认物体的细节结构,还能在不同实例和类别之间完结泛化。
凭仗这种强壮的表明才能,即使只运用少数标示数据和一个简略的线性模型,再加上一些轻量适配器,也能在 DINOv3上完结稳健的密布猜测作用。假如再结合更杂乱的解码器,乃至能够在无需对主干模型进行微调的前提下,在方针检测、语义切割和相对深度估量等经典核算机视觉使命中到达当时最先进的水平。
因为无需微调,在一次前向核算中,DINOv3 就能一起服务于多个视觉使命,然后多个使命能够同享核算开支。
这关于那些在边际设备上需求并行履行多项视觉处理的场景尤为要害。
DINOv3超卓的通用性和高效率,使它成为此类运用的抱负挑选。
NASA的喷气推动实验室(JPL)现已在运用 DINOv2 构建火星勘探机器人,完结了在极低核算资源下完结多项视觉使命的方针。
合适实践布置,多个模型全开源
DINOv3扩展到了70亿参数规划,充沛展现了自监督学习(SSL)的潜力,但这样的大模型关于许多实践运用来说并不实践。
因而,Meta构建了一个模型宗族,掩盖从轻量级到高功能的不同核算需求,以满意各类研讨和开发场景。
经过将ViT-7B蒸馏成更小但功能优越的版别(如ViT-B和ViT-L),DINOv3在多个评价使命中均逾越了同类的CLIP模型。
此外,他们还推出了一系列根据ViT-7B蒸馏的ConvNeXt架构(T、S、B、L),适用于不同核算资源约束下的布置需求。
一起,他们也开放了完好的蒸馏流程,便于社区在此根底上持续拓宽。
参考资料:
https://ai.meta.com/blog/dinov3-self-supervised-vision-model/
https://ai.meta.com/dinov3/
https://ai.meta.com/blog/nasa-jpl-dino-robot-explorers/
https://ai.meta.com/research/publications/dinov3/
本文来自微信大众号“新智元”,修改:KingHZ ,36氪经授权发布。